Jsoup을 이용한 웹 크롤링은 tosuccess.tistory.com/119 을 참고하세요!
공공 데이터 XML 크롤링은 tosuccess.tistory.com/150 을 참고하세요!
오늘은 STATIZ라는 스포츠 기록 사이트에서 야구(투수)에 관련된 랭킹을 2011년도부터 2020년까지의 데이터를 크롤링하여 DataFrame으로 만들고 csv로 변환시켜 로컬에 저장하는 것까지 해보겠다.

내가 원하는건 모든 데이터를 원하지만 옵션에서 출력할 수 있는 개수는 100이 제한되어있다.
웹을 조금 다뤄본 사람이라면,
www.statiz.co.kr/stat.php?mid=stat&re=1&ys=2011&ye=2020&se=0&te=&tm=&ty=0&qu=auto&po=0&as=&ae=&hi=&un=&pl=&da=1&o1=WAR&o2=OutCount&de=1&lr=0&tr=&cv=&ml=1&pa=0&si=&cn=&sn=100 (실제URL) 이런 식의 Url에서 ?name=1 등 같은 데이터는 파라미터를 의미하는 것을 알 거라고 생각한다.
출력을 100으로 검색했을 때, Url 마지막 부분 sn파라미터가 100을 가리킨다. 저기를 조금 수정해서 크롤링해볼 수 있을 것이다.

그다음에는 Selenium으로 웹 크롤링을 실행합니다.
(Selenium으로 크롤링하는 이유 : 현재 페이지는 Html 파일이 아닌, 데이터를 처리해서 보여주는 동적 웹사이트이다. 동적 웹사이트는 기본 크롤링으로 크롤링되지 않으며, 자세한 내용은 동적 웹페이지와 정적 웹페이지의 차이를 구글에 쳐보는 것을 추천한다.)
다음은 Colab에서 해당 데이터를 가져오기 위한 로직이다.
1. 라이브러리 install
!pip install selenium # 동적 웹페이지를 크롤링하기 위한 라이브러리
!pip install urllib
!pip install pandas
!pip install beautifulsoup4 # 정적 웹페이지를 크롤링을 할 수 있는 라이브러리
!apt install chromium-chromedriver # 크롬드라이버
*Selenium은 깔려있는 크롬 버전의 크롬 드라이버를 사용해야하는데 코랩에서는 자동으로 해결된다!
2. 라이브러리 import 및 크롬드라이버 설정
from selenium import webdriver
from bs4 import BeautifulSoup
import pandas as pd
#크롬 드라이버 버전 확인 Chrome://version
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless') #내부 창을 띄울 수 없으므로 설정
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
chromeDriver = webdriver.Chrome('chromedriver',chrome_options=chrome_options)
3. 크롤링 및 html parsing
chromeDriver.get("http://www.statiz.co.kr/stat.php?mid=stat&re=1&ys=2011&ye=2020&se=0&te=&tm=&ty=0&qu=auto&po=0&as=&ae=&hi=&un=&pl=&da=1&o1=WAR&o2=OutCount&de=1&lr=0&tr=&cv=&ml=1&pa=0&si=&cn=&sn=5000")
#사용할 URL
html = chromeDriver.page_source
bsObject = BeautifulSoup(html, 'html.parser')*Selenuim으로 크롤링한 페이지를 (개인적인 편의상) BeautifulSoup라는 라이브러리를 이용해 parsing 해준다.
4. 크롤링을 원하는 페이지 element 고르기

*나는 table 중 2번째 있는 mytable이라는 id값을 가진 테이블을 골랐다.
temp = bsObject.find_all("table")[1]
temp*find("태그 이름")는 가장 먼저 있는 태그에 있는 내용들을 가져오고
find_all("태그 이름")은 태그에 해당하는 전체 내용을 가져오게 된다.

<table id =mytable> 안에 있는 수도 없이 많은 tr들이 나오게 된다.
이제 이 부분을 전처리해주면 된다.(할 땐 막막했다..)
5. 전처리 해주기
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
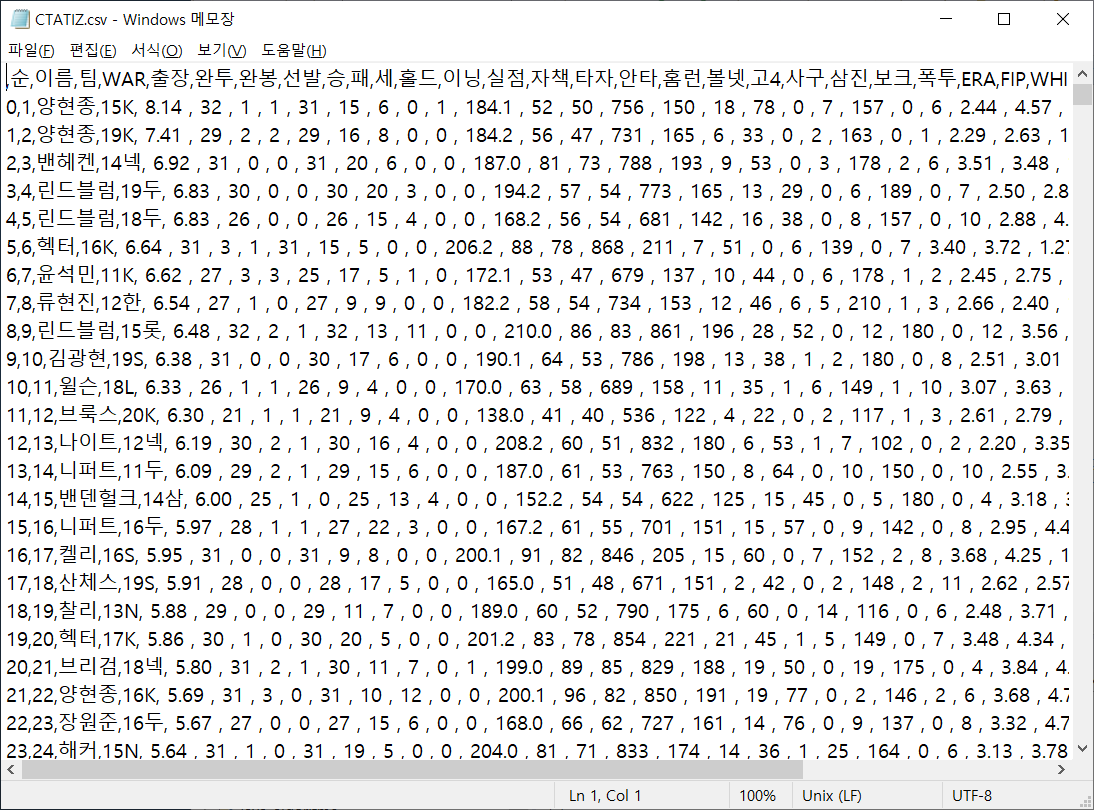
column = ["순","이름","팀","WAR","출장","완투","완봉","선발","승","패","세","홀드","이닝","실점","자책","타자","안타","홈런","볼넷","고4","사구","삼진","보크","폭투","ERA","FIP","WHIP","ERA+","FIP+","WAR"]
df = pd.DataFrame(columns=column)
templen = len(temp.find_all("tr"))
for i in range(2, templen):
tempTr = temp.find_all("tr")[i]
if(tempTr.find("th") is not None):
continue
row = {}
column_idx = 0
for j in range(32):
tempTd = tempTr.find_all("td")[j].text
if(tempTd == "" and j > 0):
continue
row[column[column_idx]] = tempTd
column_idx += 1
df = df.append(row,ignore_index=True)
|
cs |
*이 부분은 보기 쉽게 Color Scripter을 적용했다.

칼럼은 이런 식으로 나와있기 때문에 데이터 전처리하면서 뽑아내는 것보다 미리 지정하고 하는 것이 편해 보여 먼저 설정했다.
코드를 뜯어보자면,
range(2, templen)을 해준 이유는 첫 tr 2개는 선수 정보가 아닌 다른 데이터가 나오기 때문에 제외했다.
tempTr.find("th") is not None은 선수 정보 10개당 아래같이 나오기 때문에 선수 정보만 뽑기 위한 로직이다.

row는 데이터 프레임에 넣어줄 한 개의 행, column_idx는 column에 맞게 row에 저장하기 쉽게 해주는 index다.
if(tempTd == "" and j > 0): 은 중간에 2타, 3타가 비어있기에 적용해주었다.
df = df.append(row,ignore_index=True) 한 행에 대해 쌓은 row(행) 데이터를 데이터 프레임에 차곡차곡 쌓는 코드다.
6. 데이터 프레임 보기
df
2타, 3타를 제외한 30 칼럼에 대한 2293행이 전부 데이터프레임으로 만들어졌다.
7. csv를 만들어 로컬에 저장하기.
from google.colab import files
df.to_csv("CTATIZ.csv")
files.download("CTATIZ.csv")해당 코드를 실행하면 아래와 같은 창이 뜬다. 원하는 로컬에 저장해주면 끝!

*혹시 2015년도 이후 데이터 중 2011~2015 같은 범위가 아닌 단일 연도의 데이터를 가져오고 싶으신 분은 columns에 2타, 3타를 추가하셔야 합니다!
같이 보면 좋은 사이트!
Selenium -
velog.io/@swhybein/Python-Selenium%EC%9C%BC%EB%A1%9C-%ED%81%AC%EB%A1%A4%EB%A7%81%ED%95%98%EA%B8%B0
dataitgirls2.github.io/tutorial/Tutorial_180719_BeautifulSoup.html
Beautifulsoup로 학식 테이블 스크래핑하기-
throughkim.kr/2016/04/01/beautifulsoup/
Selenium으로 네이버 연극 데이터 크롤링하기 - teamlab.github.io/jekyllDecent/blog/crawling%20with%20python/Selenium%EC%9C%BC%EB%A1%9C-%EB%84%A4%EC%9D%B4%EB%B2%84-%EC%97%B0%EA%B7%B9-%EB%8D%B0%EC%9D%B4%ED%84%B0-%ED%81%AC%EB%A1%A4%EB%A7%81%ED%95%98%EA%B8%B0-with-Python
웹 크롤링에 사용하는 Beautiful Soup(뷰티플 수프) 사용법과 예제 -
twpower.github.io/84-how-to-use-beautiful-soup
csv로 저장하기 - www.dreamy.pe.kr/zbxe/CodeClip/3769485
'빅데이터 | 머신러닝 | 딥러닝 > 빅데이터 분석' 카테고리의 다른 글
| [pandas] 공공 데이터 XML 크롤링을 통해 dataFrame으로 만들어보기 (0) | 2020.09.04 |
|---|---|
| [pandas] 코로나 수치 예측하기 (feat. Linear Regression) (0) | 2020.05.03 |
| spark를 이용해서 Missing Data다루기 (0) | 2020.04.29 |
| spark를 이용해서 Sales 정보 다루기(using groupBy, orderBy) (0) | 2020.04.23 |
| spark를 이용해서 삼성전자 주식 분석하기 (0) | 2020.04.15 |